Let's Imagine a Case:
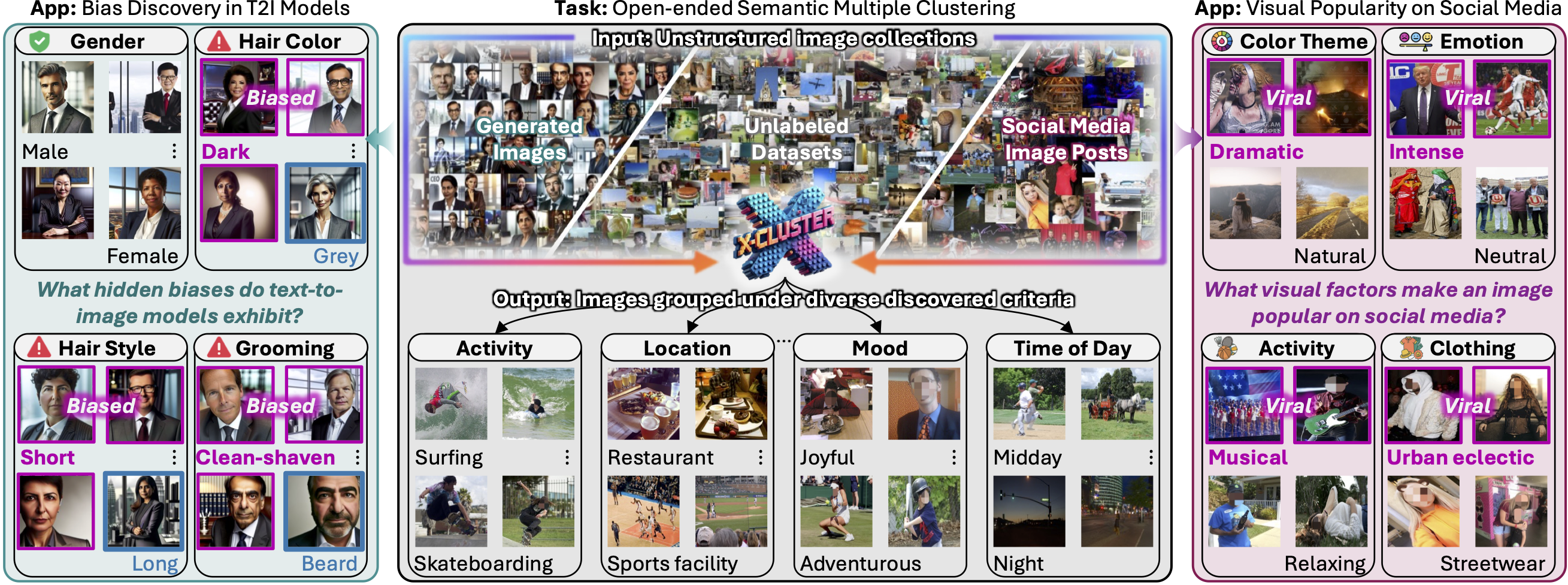
It's a normal day as an analyst at a social media company like Instagram or Rednote. You open your laptop to a million new images—your task: figuring out what content are your users uploading and what's trending. Usually, you tag images into known categories under some predefined topics (Sports, Tech, Beauty...) to sort these images. But is that enough? What about the emerging topics you haven't thought of yet?
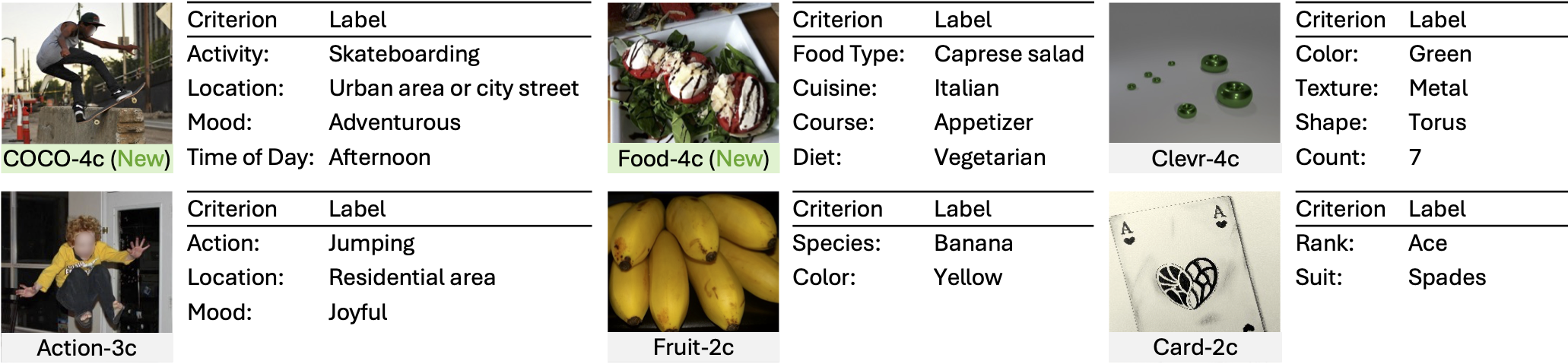
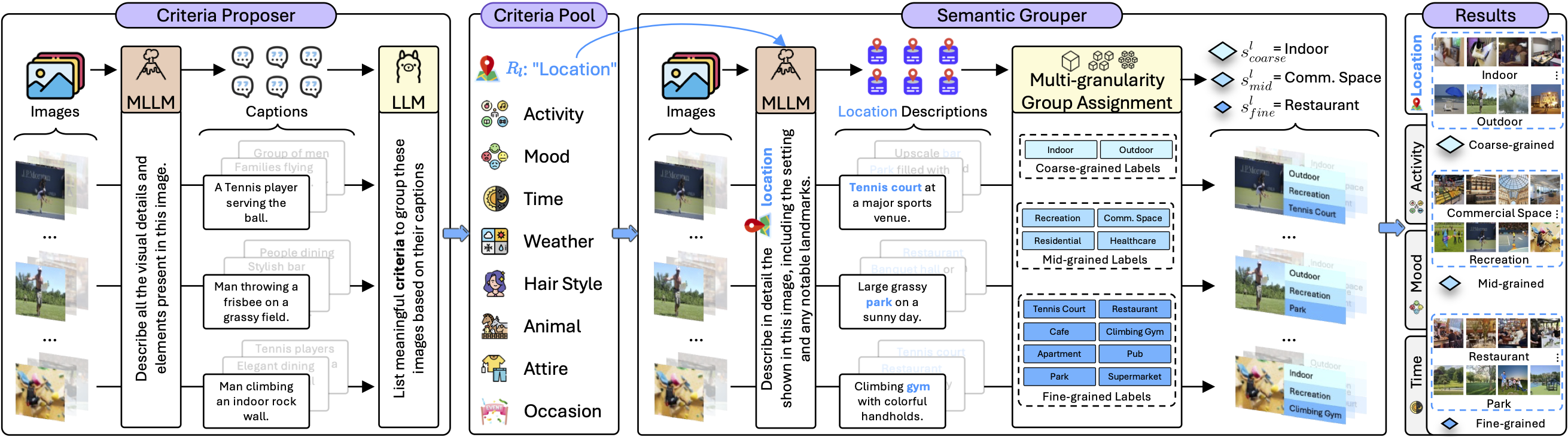
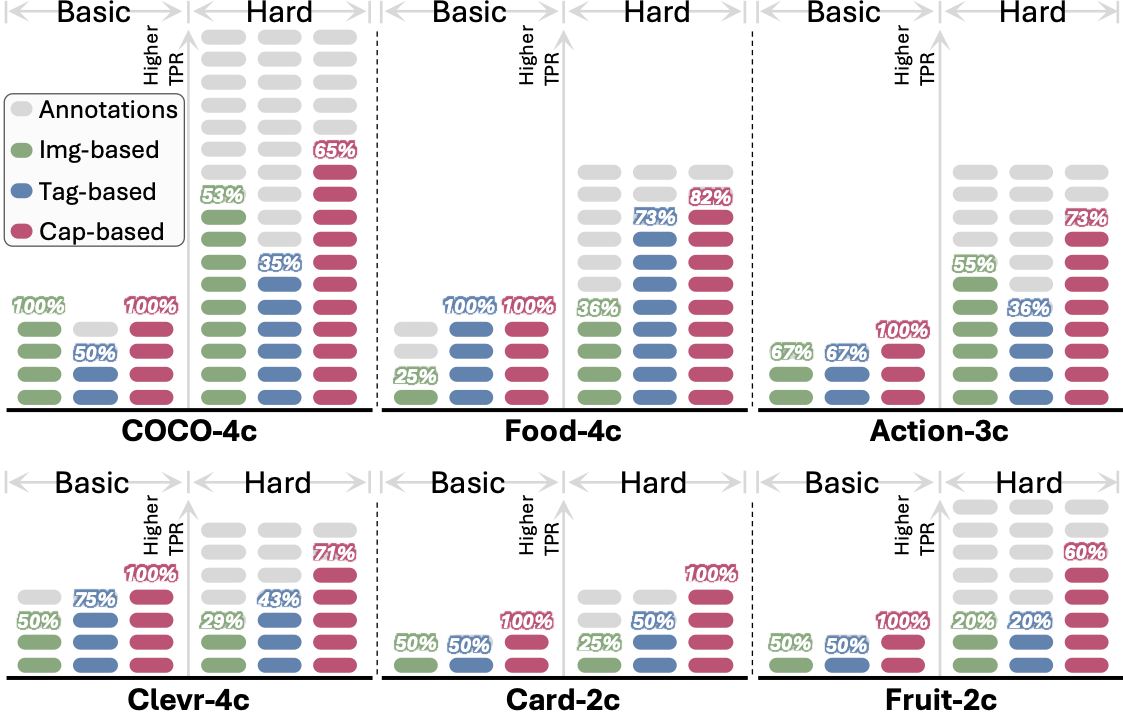
Meet X-Cluster. It automatically explores massive, unstructured image collections to discover meaningful and interpretable grouping criteria and organize the images for you—no predefined rules, no manual effort. It doesn't just sort the images; it identifies new, hidden distribution directly from the visual data. Just sit back and explore today's fresh insights, discover hidden opportunities, and stay ahead effortlessly.
Sounds great, right? Grazie!
 Organizing Unstructured Image Collections using Natural Language
Organizing Unstructured Image Collections using Natural Language